Pryon Appoints AI Veteran Hamsa Buvaraghan as SVP/Head of Product
Google and Microsoft Product Veteran Joins Pryon to Lead Company's Enterprise AI Memory Vision and Strategy

Why a RAG architecture matters, what it looks like, and how to ensure yours meets your organization’s needs
Organizations that want to implement generative AI (GenAI) in their businesses have increasingly looked to retrieval-augmented generation, or RAG, as a foundational framework. With RAG, the generative outputs of an AI application are based on a trustworthy source, such as a company’s knowledge base, ensuring accuracy, speed, and security.
Doing RAG properly requires putting together an architecture that’s right for your organization. It’s a bit like building a house: you wouldn’t lay the foundation without ensuring you have a solid blueprint for the entire building, so why would you try to implement a RAG-based AI application without the right architecture in place?
The best RAG architecture ensures a great implementation and, ultimately, a safe and trustworthy deployment. In this article, we’ll explore what a RAG architecture should include, what it looks like in practice, mistakes to avoid, and more.
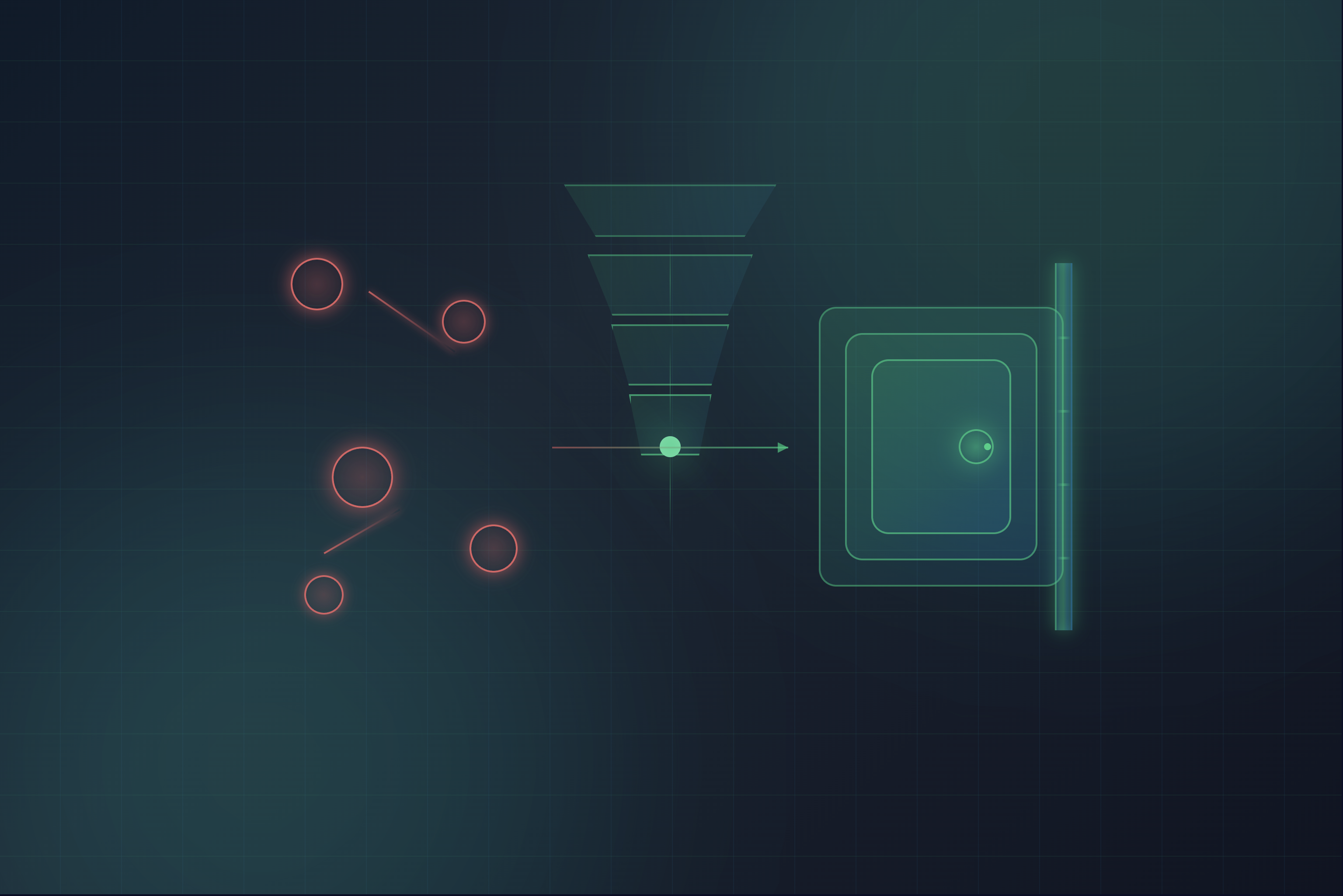
Put simply, a RAG architecture defines the structure of a RAG-based AI application. It includes the key components that make RAG possible, such as an ingestion engine, retrieval engine, and generative engine. A RAG architecture also includes the foundational elements critical to any business-ready application, such as a security layer and platform configuration capabilities.
Since AI emerged on the scene just a few years ago, organizations have eagerly explored the deployment of AI applications to unlock new workflows, accelerate existing ones, and drive productivity like never before. After playing around with consumer-grade generative AI tools like ChatGPT, enterprises found that these tools could hallucinate, or make up answers, instead of simply admitting they didn’t know the answer to every question. This isn’t exactly ideal for an enterprise AI application.
Retrieval-augmented generation (RAG) has emerged as an ideal way to implement AI responsibly. AI applications built on a RAG framework retrieve information from a trusted knowledge library before delivering responses to users. This is different from how tools like ChatGPT work; those tools have been trained to sound intelligent, like another human, but in reality they’re more like sophisticated autocomplete systems.
Not all RAG solutions are equal, though. Organizations — especially large ones — that must ensure their AI applications prioritize accuracy, privacy, speed, security, and other capabilities need an enterprise-grade RAG architecture. A RAG architecture built for the enterprise is capable of:
LEARN MORE: Retrieval-Augmented Generation Tutorial:
Master RAG for Your Enterprise
An enterprise RAG architecture includes everything needed for a large organization to implement RAG at scale. At a high level, here’s what one looks like:

Now that you’ve got an overview of what’s included in a RAG architecture, let’s take a closer look at the many pieces that make a RAG application tick.
RECOMMENDED READING: RAG Definition and LLM Glossary
Any ingestion engine reads content, but the best ingestion engine can read content just like a human would. This is made possible through:
RAG simply isn’t possible with a retrieval engine. You can ingest all the content you want, but if you can’t properly match queries to that content, the RAG application won’t work. The capabilities of a RAG retrieval engine can be separated into two categories:
Of the three engines included in an enterprise RAG architecture, the generative engine is the one that users will interact with most — and whose underperformance will be most obvious. Here’s what a generative engine should include to ensure users get the responses they’re expecting:
The time to implement a RAG architecture can vary between enterprises. Unfortunately, many AI applications take many months to deploy, owing to the time needed to scope a business case, determine technical feasibility, source and prepare data, build and test models, and actually implement. On the other hand, enterprises that adopt the pre-built Pryon RAG Suite can be production-ready in just 2-6 weeks.
Why do I need a RAG architecture?
If you’re serious about deploying a RAG-based AI application in a thoughtful manner, you need a RAG architecture. A RAG architecture includes the key elements that make Enterprise RAG possible, including a security layer, platform configuration capabilities, and ingestion, retrieval, and generative engines.
Can I implement an enterprise RAG architecture quickly?
With Pryon RAG Suite, you can implement an enterprise-class RAG architecture in just 2-6 weeks. Within this short period of time, you can scope, build, and test multiple use cases; connect your RAG application directly with your existing content sources; and get help from Pryon’s solution experts.
Should I cobble together my own RAG architecture, or go with a prebuilt RAG architecture?
The decision to build or buy an enterprise AI application is complex. In general, if your goal is to develop a single or a couple of bespoke applications, a custom-built solution might make sense. However, if you envision a broader enterprise RAG architecture to support multiple applications across various departments, a proven, purpose-built platform could provide greater value and scalability. Purchased solutions have often been better tested, offer more support, and boast more security features, reducing the risks associated with custom development.
Should my RAG architecture be totally verticalized, or can I use a RAG architecture composed of parts from multiple companies?
If you’re starting from scratch, it would likely be easier and less expensive to choose a single vendor for the many components of your RAG architecture. However, some organizations that already have some aspects of a RAG architecture in place (e.g., a generative engine they’re already comfortable with and that they’ve already built a front-end interface around) may choose to get other parts of the RAG stack, such as the ingestion and retrieval pieces, from a vendor like Pryon that offers modular solutions for RAG application builders.
Why does data governance matter, and what's included in it?
As companies integrate generative AI applications (including those built on a RAG framework) into their systems, they must align these implementations with established data governance pillars to maintain data integrity, security, and compliance. These pillars include data quality, data security & privacy, data architecture & integration, metadata management, data lifecycle management, regulatory compliance, and data stewardship.
Why a RAG architecture matters, what it looks like, and how to ensure yours meets your organization’s needs
Organizations that want to implement generative AI (GenAI) in their businesses have increasingly looked to retrieval-augmented generation, or RAG, as a foundational framework. With RAG, the generative outputs of an AI application are based on a trustworthy source, such as a company’s knowledge base, ensuring accuracy, speed, and security.
Doing RAG properly requires putting together an architecture that’s right for your organization. It’s a bit like building a house: you wouldn’t lay the foundation without ensuring you have a solid blueprint for the entire building, so why would you try to implement a RAG-based AI application without the right architecture in place?
The best RAG architecture ensures a great implementation and, ultimately, a safe and trustworthy deployment. In this article, we’ll explore what a RAG architecture should include, what it looks like in practice, mistakes to avoid, and more.
Put simply, a RAG architecture defines the structure of a RAG-based AI application. It includes the key components that make RAG possible, such as an ingestion engine, retrieval engine, and generative engine. A RAG architecture also includes the foundational elements critical to any business-ready application, such as a security layer and platform configuration capabilities.
Since AI emerged on the scene just a few years ago, organizations have eagerly explored the deployment of AI applications to unlock new workflows, accelerate existing ones, and drive productivity like never before. After playing around with consumer-grade generative AI tools like ChatGPT, enterprises found that these tools could hallucinate, or make up answers, instead of simply admitting they didn’t know the answer to every question. This isn’t exactly ideal for an enterprise AI application.
Retrieval-augmented generation (RAG) has emerged as an ideal way to implement AI responsibly. AI applications built on a RAG framework retrieve information from a trusted knowledge library before delivering responses to users. This is different from how tools like ChatGPT work; those tools have been trained to sound intelligent, like another human, but in reality they’re more like sophisticated autocomplete systems.
Not all RAG solutions are equal, though. Organizations — especially large ones — that must ensure their AI applications prioritize accuracy, privacy, speed, security, and other capabilities need an enterprise-grade RAG architecture. A RAG architecture built for the enterprise is capable of:
LEARN MORE: Retrieval-Augmented Generation Tutorial:
Master RAG for Your Enterprise
An enterprise RAG architecture includes everything needed for a large organization to implement RAG at scale. At a high level, here’s what one looks like:
Now that you’ve got an overview of what’s included in a RAG architecture, let’s take a closer look at the many pieces that make a RAG application tick.
RECOMMENDED READING: RAG Definition and LLM Glossary
Any ingestion engine reads content, but the best ingestion engine can read content just like a human would. This is made possible through:
RAG simply isn’t possible with a retrieval engine. You can ingest all the content you want, but if you can’t properly match queries to that content, the RAG application won’t work. The capabilities of a RAG retrieval engine can be separated into two categories:
Of the three engines included in an enterprise RAG architecture, the generative engine is the one that users will interact with most — and whose underperformance will be most obvious. Here’s what a generative engine should include to ensure users get the responses they’re expecting:
The time to implement a RAG architecture can vary between enterprises. Unfortunately, many AI applications take many months to deploy, owing to the time needed to scope a business case, determine technical feasibility, source and prepare data, build and test models, and actually implement. On the other hand, enterprises that adopt the pre-built Pryon RAG Suite can be production-ready in just 2-6 weeks.
Why do I need a RAG architecture?
If you’re serious about deploying a RAG-based AI application in a thoughtful manner, you need a RAG architecture. A RAG architecture includes the key elements that make Enterprise RAG possible, including a security layer, platform configuration capabilities, and ingestion, retrieval, and generative engines.
Can I implement an enterprise RAG architecture quickly?
With Pryon RAG Suite, you can implement an enterprise-class RAG architecture in just 2-6 weeks. Within this short period of time, you can scope, build, and test multiple use cases; connect your RAG application directly with your existing content sources; and get help from Pryon’s solution experts.
Should I cobble together my own RAG architecture, or go with a prebuilt RAG architecture?
The decision to build or buy an enterprise AI application is complex. In general, if your goal is to develop a single or a couple of bespoke applications, a custom-built solution might make sense. However, if you envision a broader enterprise RAG architecture to support multiple applications across various departments, a proven, purpose-built platform could provide greater value and scalability. Purchased solutions have often been better tested, offer more support, and boast more security features, reducing the risks associated with custom development.
Should my RAG architecture be totally verticalized, or can I use a RAG architecture composed of parts from multiple companies?
If you’re starting from scratch, it would likely be easier and less expensive to choose a single vendor for the many components of your RAG architecture. However, some organizations that already have some aspects of a RAG architecture in place (e.g., a generative engine they’re already comfortable with and that they’ve already built a front-end interface around) may choose to get other parts of the RAG stack, such as the ingestion and retrieval pieces, from a vendor like Pryon that offers modular solutions for RAG application builders.
Why does data governance matter, and what's included in it?
As companies integrate generative AI applications (including those built on a RAG framework) into their systems, they must align these implementations with established data governance pillars to maintain data integrity, security, and compliance. These pillars include data quality, data security & privacy, data architecture & integration, metadata management, data lifecycle management, regulatory compliance, and data stewardship.
Why a RAG architecture matters, what it looks like, and how to ensure yours meets your organization’s needs
Organizations that want to implement generative AI (GenAI) in their businesses have increasingly looked to retrieval-augmented generation, or RAG, as a foundational framework. With RAG, the generative outputs of an AI application are based on a trustworthy source, such as a company’s knowledge base, ensuring accuracy, speed, and security.
Doing RAG properly requires putting together an architecture that’s right for your organization. It’s a bit like building a house: you wouldn’t lay the foundation without ensuring you have a solid blueprint for the entire building, so why would you try to implement a RAG-based AI application without the right architecture in place?
The best RAG architecture ensures a great implementation and, ultimately, a safe and trustworthy deployment. In this article, we’ll explore what a RAG architecture should include, what it looks like in practice, mistakes to avoid, and more.
Put simply, a RAG architecture defines the structure of a RAG-based AI application. It includes the key components that make RAG possible, such as an ingestion engine, retrieval engine, and generative engine. A RAG architecture also includes the foundational elements critical to any business-ready application, such as a security layer and platform configuration capabilities.
Since AI emerged on the scene just a few years ago, organizations have eagerly explored the deployment of AI applications to unlock new workflows, accelerate existing ones, and drive productivity like never before. After playing around with consumer-grade generative AI tools like ChatGPT, enterprises found that these tools could hallucinate, or make up answers, instead of simply admitting they didn’t know the answer to every question. This isn’t exactly ideal for an enterprise AI application.
Retrieval-augmented generation (RAG) has emerged as an ideal way to implement AI responsibly. AI applications built on a RAG framework retrieve information from a trusted knowledge library before delivering responses to users. This is different from how tools like ChatGPT work; those tools have been trained to sound intelligent, like another human, but in reality they’re more like sophisticated autocomplete systems.
Not all RAG solutions are equal, though. Organizations — especially large ones — that must ensure their AI applications prioritize accuracy, privacy, speed, security, and other capabilities need an enterprise-grade RAG architecture. A RAG architecture built for the enterprise is capable of:
LEARN MORE: Retrieval-Augmented Generation Tutorial:
Master RAG for Your Enterprise
An enterprise RAG architecture includes everything needed for a large organization to implement RAG at scale. At a high level, here’s what one looks like:
Now that you’ve got an overview of what’s included in a RAG architecture, let’s take a closer look at the many pieces that make a RAG application tick.
RECOMMENDED READING: RAG Definition and LLM Glossary
Any ingestion engine reads content, but the best ingestion engine can read content just like a human would. This is made possible through:
RAG simply isn’t possible with a retrieval engine. You can ingest all the content you want, but if you can’t properly match queries to that content, the RAG application won’t work. The capabilities of a RAG retrieval engine can be separated into two categories:
Of the three engines included in an enterprise RAG architecture, the generative engine is the one that users will interact with most — and whose underperformance will be most obvious. Here’s what a generative engine should include to ensure users get the responses they’re expecting:
The time to implement a RAG architecture can vary between enterprises. Unfortunately, many AI applications take many months to deploy, owing to the time needed to scope a business case, determine technical feasibility, source and prepare data, build and test models, and actually implement. On the other hand, enterprises that adopt the pre-built Pryon RAG Suite can be production-ready in just 2-6 weeks.
Why do I need a RAG architecture?
If you’re serious about deploying a RAG-based AI application in a thoughtful manner, you need a RAG architecture. A RAG architecture includes the key elements that make Enterprise RAG possible, including a security layer, platform configuration capabilities, and ingestion, retrieval, and generative engines.
Can I implement an enterprise RAG architecture quickly?
With Pryon RAG Suite, you can implement an enterprise-class RAG architecture in just 2-6 weeks. Within this short period of time, you can scope, build, and test multiple use cases; connect your RAG application directly with your existing content sources; and get help from Pryon’s solution experts.
Should I cobble together my own RAG architecture, or go with a prebuilt RAG architecture?
The decision to build or buy an enterprise AI application is complex. In general, if your goal is to develop a single or a couple of bespoke applications, a custom-built solution might make sense. However, if you envision a broader enterprise RAG architecture to support multiple applications across various departments, a proven, purpose-built platform could provide greater value and scalability. Purchased solutions have often been better tested, offer more support, and boast more security features, reducing the risks associated with custom development.
Should my RAG architecture be totally verticalized, or can I use a RAG architecture composed of parts from multiple companies?
If you’re starting from scratch, it would likely be easier and less expensive to choose a single vendor for the many components of your RAG architecture. However, some organizations that already have some aspects of a RAG architecture in place (e.g., a generative engine they’re already comfortable with and that they’ve already built a front-end interface around) may choose to get other parts of the RAG stack, such as the ingestion and retrieval pieces, from a vendor like Pryon that offers modular solutions for RAG application builders.
Why does data governance matter, and what's included in it?
As companies integrate generative AI applications (including those built on a RAG framework) into their systems, they must align these implementations with established data governance pillars to maintain data integrity, security, and compliance. These pillars include data quality, data security & privacy, data architecture & integration, metadata management, data lifecycle management, regulatory compliance, and data stewardship.
Latest ideas from Pryon.
Latest insights from Pryon.
Latest ideas from Pryon.
Latest ideas from Pryon.
Latest ideas from Pryon.
Latest ideas from Pryon.