Pryon Appoints AI Veteran Hamsa Buvaraghan as SVP/Head of Product
Google and Microsoft Product Veteran Joins Pryon to Lead Company's Enterprise AI Memory Vision and Strategy

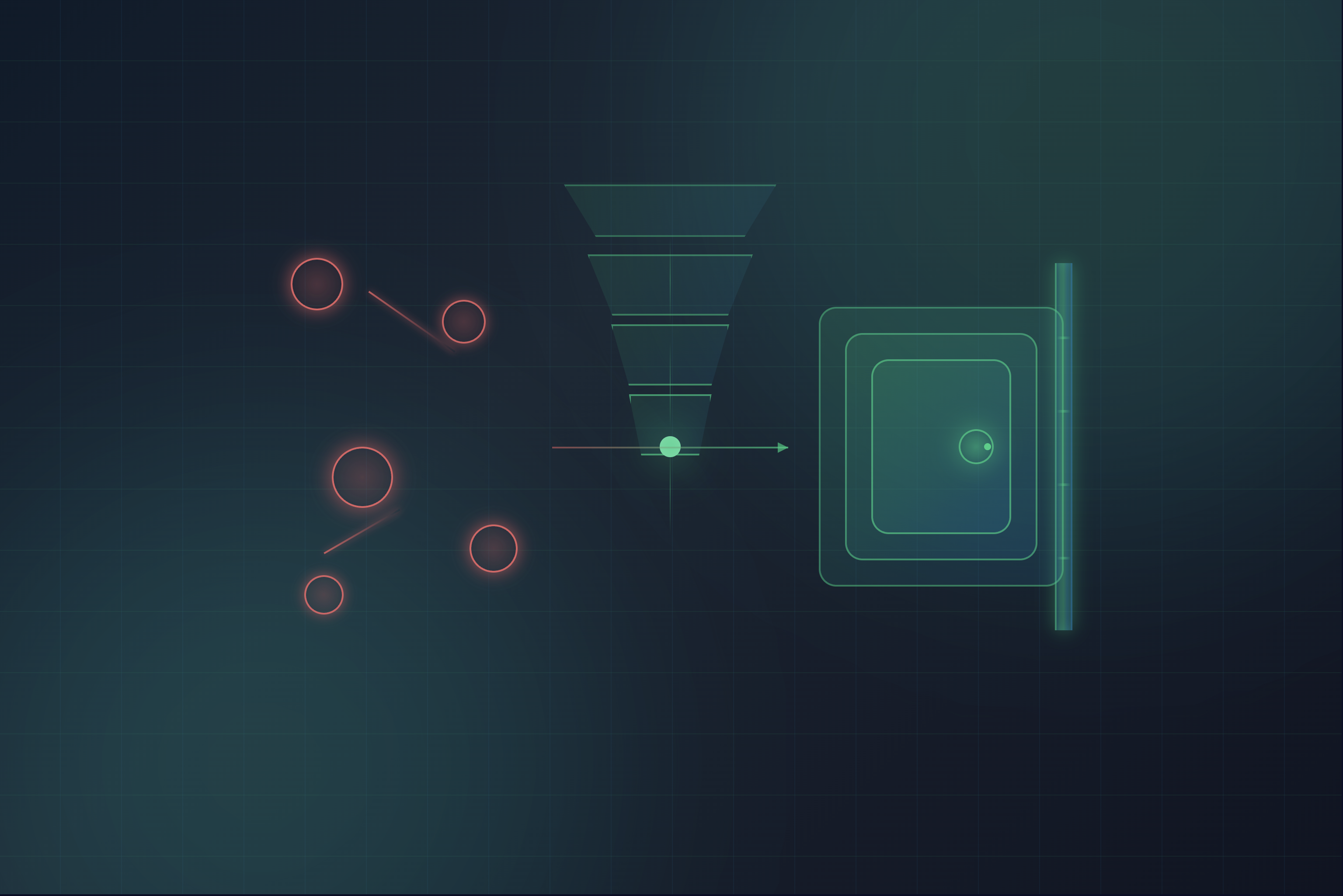
The emergence of retrieval-augmented generation (RAG) has revealed new possibilities in artificial intelligence by combining retrieval mechanisms with generative models to produce more accurate and contextually aware responses.
To successfully implement an enterprise-level RAG system, you need to start with comprehensive scoping. This ensures that your RAG system not only delivers trusted accuracy but also scales to meet enterprise demands, complies with stringent security and data governance standards, and delivers measurable value.
This article outlines the key steps necessary for scoping a RAG implementation and features two downloadable templates to help you embark on your enterprise RAG journey.
Ready to learn how to implement retrieval-augmented generation? The first step in planning a RAG implementation is to identify and prioritize potential use cases. RAG systems can support a wide range of business processes for internal stakeholders, such as sales, customer service, marketing, and R&D, as well as external stakeholders, including your customers, partners, and suppliers.
Focus on opportunities where improved access to and interaction with enterprise content can significantly enhance productivity, efficiency, and user experience. Pay special attention to complex, repetitive tasks that are essential to your workflows yet tedious to execute. Examples of such use cases include customer service automation, complex query answering, and content-intensive workflows like equipment maintenance.
Assess whether the RAG use case you are developing will achieve any of the following objectives:
Evaluate the simplicity or complexity of integrating your RAG system by considering the following questions in relation to your organization:
The more often you respond "Yes" to a specific use case, the easier its implementation will be. For instance, if you’ve decided to start with a customer support chatbot, you likely know where most of this knowledge is stored and how to build a chatbot that meets your customers’ needs.
To prioritize your RAG use cases, start by assessing the potential value and the ease of implementation for each one. Use the prompts provided above as a guiding framework for your assessment.
A simple matrix can help you visualize your AI use case prioritization (download yours here). Place the potential value of a RAG use case on one axis and the ease of implementation on the other. From there, plan your implementation strategy, focusing first on use cases that offer high value and high ease of implementation.
It might look something like this.

In this example, the RAG use cases we should prioritize are a sales support chatbot and a customer self-service tool, as both are high-value options that are easy to implement.
DOWNLOAD NOW
AI Use Case Prioritization Framework Template
Once you've evaluated and prioritized your RAG use cases, you can work on defining the scope of the ones you’ve identified as top priority. Follow these eight steps to effectively scope a RAG use case (or follow along with our downloadable checklist template):
A clear understanding of your RAG system's users is crucial for informing design decisions and tailoring the user experience to meet their specific needs.
Define the types of queries the RAG system will manage. This includes:
Identifying typical query types and levels of complexity will help you design the retrieval and generative components of your RAG system.
Identify the platforms and environment from which users will access the RAG system, such as:
Knowing where and how users will access your RAG system is important for designing user experiences so you can ensure great interactions across various platforms.
Consider the following potential guardrail capabilities for your RAG system:
Implementing guardrails ensures the RAG system operates within acceptable boundaries. Guardrails protect against misuse, minimize the scope for hallucinations or biases, and help maintain system reliability and trustworthiness.
Accurately sizing your RAG infrastructure is crucial for performance and scalability.
DOWNLOAD NOW
Ultimate Checklist for Scoping an AI Use Case
Implementing a RAG system generally consists of six key phases:
Building a RAG system from the ground up requires you to complete all of the steps above, with AI implementation timelines potentially stretching to 6-9 months.
Using a pre-built RAG platform like Pryon RAG Suite allows you to bypass several time-consuming steps, significantly shortening the implementation timeline to just 2-6 weeks.
Accurately estimating resources and budget is essential for effective project planning and securing approval. When calculating the costs associated with your RAG implementation, consider the following factors:
Develop a detailed budget that covers all aspects of the project, from initial development to long-term maintenance and support.
Choosing a pre-built RAG platform like Pryon RAG Suite can significantly lower startup and scaling costs compared to building your own RAG system from scratch. This allows for more effective budgeting of your RAG deployments and leads to a greater return on investment.
Scoping a RAG implementation is a complex but rewarding endeavor. By carefully selecting and prioritizing use cases, defining detailed requirements, sizing infrastructure appropriately, and planning project phases and resources, you can start leveraging AI systems to unlock new capabilities and drive significant value.
As a high-level recap, here is a step-by-step overview of how to implement RAG:
With thorough planning and execution, RAG implementations can transform how internal and external users interact with your unstructured data, reducing knowledge friction between creators and consumers of enterprise content.
Want to learn more about what it takes to build and scale RAG in your enterprise? Download our comprehensive guide: How to Get Enterprise RAG Right.
Reach out to our team to discover how Pryon RAG Suite provides best-in-class ingestion, retrieval, and generative capabilities for building and scaling an enterprise RAG architecture.
The emergence of retrieval-augmented generation (RAG) has revealed new possibilities in artificial intelligence by combining retrieval mechanisms with generative models to produce more accurate and contextually aware responses.
To successfully implement an enterprise-level RAG system, you need to start with comprehensive scoping. This ensures that your RAG system not only delivers trusted accuracy but also scales to meet enterprise demands, complies with stringent security and data governance standards, and delivers measurable value.
This article outlines the key steps necessary for scoping a RAG implementation and features two downloadable templates to help you embark on your enterprise RAG journey.
Ready to learn how to implement retrieval-augmented generation? The first step in planning a RAG implementation is to identify and prioritize potential use cases. RAG systems can support a wide range of business processes for internal stakeholders, such as sales, customer service, marketing, and R&D, as well as external stakeholders, including your customers, partners, and suppliers.
Focus on opportunities where improved access to and interaction with enterprise content can significantly enhance productivity, efficiency, and user experience. Pay special attention to complex, repetitive tasks that are essential to your workflows yet tedious to execute. Examples of such use cases include customer service automation, complex query answering, and content-intensive workflows like equipment maintenance.
Assess whether the RAG use case you are developing will achieve any of the following objectives:
Evaluate the simplicity or complexity of integrating your RAG system by considering the following questions in relation to your organization:
The more often you respond "Yes" to a specific use case, the easier its implementation will be. For instance, if you’ve decided to start with a customer support chatbot, you likely know where most of this knowledge is stored and how to build a chatbot that meets your customers’ needs.
To prioritize your RAG use cases, start by assessing the potential value and the ease of implementation for each one. Use the prompts provided above as a guiding framework for your assessment.
A simple matrix can help you visualize your AI use case prioritization (download yours here). Place the potential value of a RAG use case on one axis and the ease of implementation on the other. From there, plan your implementation strategy, focusing first on use cases that offer high value and high ease of implementation.
It might look something like this.
In this example, the RAG use cases we should prioritize are a sales support chatbot and a customer self-service tool, as both are high-value options that are easy to implement.
DOWNLOAD NOW
AI Use Case Prioritization Framework Template
Once you've evaluated and prioritized your RAG use cases, you can work on defining the scope of the ones you’ve identified as top priority. Follow these eight steps to effectively scope a RAG use case (or follow along with our downloadable checklist template):
A clear understanding of your RAG system's users is crucial for informing design decisions and tailoring the user experience to meet their specific needs.
Define the types of queries the RAG system will manage. This includes:
Identifying typical query types and levels of complexity will help you design the retrieval and generative components of your RAG system.
Identify the platforms and environment from which users will access the RAG system, such as:
Knowing where and how users will access your RAG system is important for designing user experiences so you can ensure great interactions across various platforms.
Consider the following potential guardrail capabilities for your RAG system:
Implementing guardrails ensures the RAG system operates within acceptable boundaries. Guardrails protect against misuse, minimize the scope for hallucinations or biases, and help maintain system reliability and trustworthiness.
Accurately sizing your RAG infrastructure is crucial for performance and scalability.
DOWNLOAD NOW
Ultimate Checklist for Scoping an AI Use Case
Implementing a RAG system generally consists of six key phases:
Building a RAG system from the ground up requires you to complete all of the steps above, with AI implementation timelines potentially stretching to 6-9 months.
Using a pre-built RAG platform like Pryon RAG Suite allows you to bypass several time-consuming steps, significantly shortening the implementation timeline to just 2-6 weeks.
Accurately estimating resources and budget is essential for effective project planning and securing approval. When calculating the costs associated with your RAG implementation, consider the following factors:
Develop a detailed budget that covers all aspects of the project, from initial development to long-term maintenance and support.
Choosing a pre-built RAG platform like Pryon RAG Suite can significantly lower startup and scaling costs compared to building your own RAG system from scratch. This allows for more effective budgeting of your RAG deployments and leads to a greater return on investment.
Scoping a RAG implementation is a complex but rewarding endeavor. By carefully selecting and prioritizing use cases, defining detailed requirements, sizing infrastructure appropriately, and planning project phases and resources, you can start leveraging AI systems to unlock new capabilities and drive significant value.
As a high-level recap, here is a step-by-step overview of how to implement RAG:
With thorough planning and execution, RAG implementations can transform how internal and external users interact with your unstructured data, reducing knowledge friction between creators and consumers of enterprise content.
Want to learn more about what it takes to build and scale RAG in your enterprise? Download our comprehensive guide: How to Get Enterprise RAG Right.
Reach out to our team to discover how Pryon RAG Suite provides best-in-class ingestion, retrieval, and generative capabilities for building and scaling an enterprise RAG architecture.
The emergence of retrieval-augmented generation (RAG) has revealed new possibilities in artificial intelligence by combining retrieval mechanisms with generative models to produce more accurate and contextually aware responses.
To successfully implement an enterprise-level RAG system, you need to start with comprehensive scoping. This ensures that your RAG system not only delivers trusted accuracy but also scales to meet enterprise demands, complies with stringent security and data governance standards, and delivers measurable value.
This article outlines the key steps necessary for scoping a RAG implementation and features two downloadable templates to help you embark on your enterprise RAG journey.
Ready to learn how to implement retrieval-augmented generation? The first step in planning a RAG implementation is to identify and prioritize potential use cases. RAG systems can support a wide range of business processes for internal stakeholders, such as sales, customer service, marketing, and R&D, as well as external stakeholders, including your customers, partners, and suppliers.
Focus on opportunities where improved access to and interaction with enterprise content can significantly enhance productivity, efficiency, and user experience. Pay special attention to complex, repetitive tasks that are essential to your workflows yet tedious to execute. Examples of such use cases include customer service automation, complex query answering, and content-intensive workflows like equipment maintenance.
Assess whether the RAG use case you are developing will achieve any of the following objectives:
Evaluate the simplicity or complexity of integrating your RAG system by considering the following questions in relation to your organization:
The more often you respond "Yes" to a specific use case, the easier its implementation will be. For instance, if you’ve decided to start with a customer support chatbot, you likely know where most of this knowledge is stored and how to build a chatbot that meets your customers’ needs.
To prioritize your RAG use cases, start by assessing the potential value and the ease of implementation for each one. Use the prompts provided above as a guiding framework for your assessment.
A simple matrix can help you visualize your AI use case prioritization (download yours here). Place the potential value of a RAG use case on one axis and the ease of implementation on the other. From there, plan your implementation strategy, focusing first on use cases that offer high value and high ease of implementation.
It might look something like this.
In this example, the RAG use cases we should prioritize are a sales support chatbot and a customer self-service tool, as both are high-value options that are easy to implement.
DOWNLOAD NOW
AI Use Case Prioritization Framework Template
Once you've evaluated and prioritized your RAG use cases, you can work on defining the scope of the ones you’ve identified as top priority. Follow these eight steps to effectively scope a RAG use case (or follow along with our downloadable checklist template):
A clear understanding of your RAG system's users is crucial for informing design decisions and tailoring the user experience to meet their specific needs.
Define the types of queries the RAG system will manage. This includes:
Identifying typical query types and levels of complexity will help you design the retrieval and generative components of your RAG system.
Identify the platforms and environment from which users will access the RAG system, such as:
Knowing where and how users will access your RAG system is important for designing user experiences so you can ensure great interactions across various platforms.
Consider the following potential guardrail capabilities for your RAG system:
Implementing guardrails ensures the RAG system operates within acceptable boundaries. Guardrails protect against misuse, minimize the scope for hallucinations or biases, and help maintain system reliability and trustworthiness.
Accurately sizing your RAG infrastructure is crucial for performance and scalability.
DOWNLOAD NOW
Ultimate Checklist for Scoping an AI Use Case
Implementing a RAG system generally consists of six key phases:
Building a RAG system from the ground up requires you to complete all of the steps above, with AI implementation timelines potentially stretching to 6-9 months.
Using a pre-built RAG platform like Pryon RAG Suite allows you to bypass several time-consuming steps, significantly shortening the implementation timeline to just 2-6 weeks.
Accurately estimating resources and budget is essential for effective project planning and securing approval. When calculating the costs associated with your RAG implementation, consider the following factors:
Develop a detailed budget that covers all aspects of the project, from initial development to long-term maintenance and support.
Choosing a pre-built RAG platform like Pryon RAG Suite can significantly lower startup and scaling costs compared to building your own RAG system from scratch. This allows for more effective budgeting of your RAG deployments and leads to a greater return on investment.
Scoping a RAG implementation is a complex but rewarding endeavor. By carefully selecting and prioritizing use cases, defining detailed requirements, sizing infrastructure appropriately, and planning project phases and resources, you can start leveraging AI systems to unlock new capabilities and drive significant value.
As a high-level recap, here is a step-by-step overview of how to implement RAG:
With thorough planning and execution, RAG implementations can transform how internal and external users interact with your unstructured data, reducing knowledge friction between creators and consumers of enterprise content.
Want to learn more about what it takes to build and scale RAG in your enterprise? Download our comprehensive guide: How to Get Enterprise RAG Right.
Reach out to our team to discover how Pryon RAG Suite provides best-in-class ingestion, retrieval, and generative capabilities for building and scaling an enterprise RAG architecture.
Latest ideas from Pryon.
Latest insights from Pryon.
Latest ideas from Pryon.
Latest ideas from Pryon.
Latest ideas from Pryon.
Latest ideas from Pryon.